



goharvest is a Go implementation of the Transactional Outbox pattern for Postgres and Kafka.
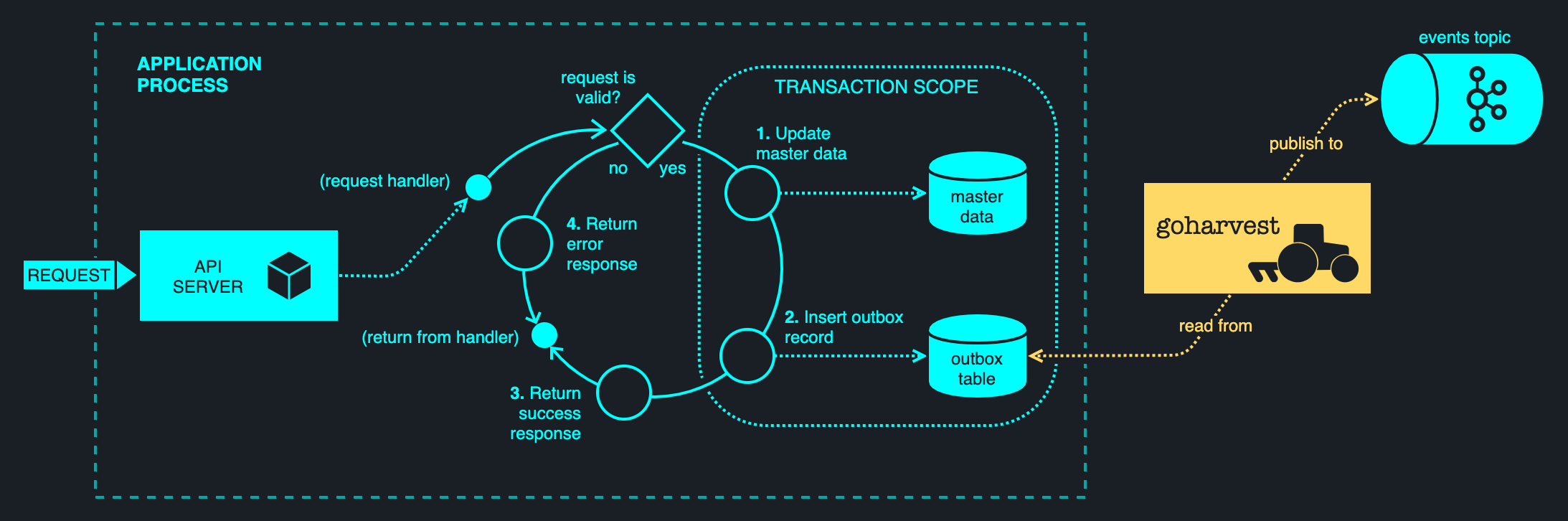
While goharvest is a complex beast, the end result is dead simple: to publish Kafka messages reliably and atomically, simply write a record to a dedicated outbox table in a transaction, alongside any other database changes. (Outbox schema provided below.) goharvest scrapes the outbox table in the background and publishes records to a Kafka topic of the application's choosing, using the key, value and headers specified in the outbox record. goharvest currently works with Postgres. It maintains causal order of messages and does not require CDC to be enabled on the database, making for a zero-hassle setup. It handles thousands of records/second on commodity hardware.
CREATE TABLE IF NOT EXISTS outbox (
id BIGSERIAL PRIMARY KEY,
create_time TIMESTAMP WITH TIME ZONE NOT NULL,
kafka_topic VARCHAR(249) NOT NULL,
kafka_key VARCHAR(100) NOT NULL, -- pick your own maximum key size
kafka_value VARCHAR(10000), -- pick your own maximum value size
kafka_header_keys TEXT[] NOT NULL,
kafka_header_values TEXT[] NOT NULL,
leader_id UUID
)This runs goharvest within a separate process called reaper, which will work alongside any application that writes to a standard outbox. (Not just applications written in Go.)
go get -u github.com/obsidiandynamics/goharvest/cmd/reaperharvest:
baseKafkaConfig:
bootstrap.servers: localhost:9092
producerKafkaConfig:
compression.type: lz4
delivery.timeout.ms: 10000
leaderTopic: my-app-name
leaderGroupID: my-app-name
dataSource: host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable
outboxTable: outbox
limits:
minPollInterval: 1s
heartbeatTimeout: 5s
maxInFlightRecords: 1000
minMetricsInterval: 5s
sendConcurrency: 4
sendBuffer: 10
logging:
level: Debugreaper -f reaper.yamlgoharvest can be run in the same process as your application.
go get -u github.com/obsidiandynamics/goharvestimport "github.com/obsidiandynamics/goharvest"// Configure the harvester. It will use its own database and Kafka connections under the hood.
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
}
// Create a new harvester.
harvest, err := New(config)
if err != nil {
panic(err)
}
// Start harvesting in the background.
err = harvest.Start()
if err != nil {
panic(err)
}
// Wait indefinitely for the harvester to end.
log.Fatal(harvest.Await())goharvest uses log.Printf for output by default. Logger configuration is courtesy of the Scribe façade, from libstdgo. The example below uses a Logrus binding for Scribe.
import (
"github.com/obsidiandynamics/goharvest"
scribelogrus "github.com/obsidiandynamics/libstdgo/scribe/logrus"
"github.com/sirupsen/logrus"
)log := logrus.StandardLogger()
log.SetLevel(logrus.DebugLevel)
// Configure the custom logger using a binding.
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
Scribe: scribe.New(scribelogrus.Bind()),
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
}Just like goharvest uses NELI to piggy-back on Kafka's leader election, you can piggy-back on goharvest to get leader status updates:
log := logrus.StandardLogger()
log.SetLevel(logrus.TraceLevel)
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
Scribe: scribe.New(scribelogrus.Bind()),
}
// Create a new harvester and register an event hander.
harvest, err := New(config)
// Register a handler callback, invoked when an event occurs within goharvest.
// The callback is completely optional; it lets the application piggy-back on leader
// status updates, in case it needs to schedule some additional work (other than
// harvesting outbox records) that should only be run on one process at any given time.
harvest.SetEventHandler(func(e Event) {
switch event := e.(type) {
case LeaderAcquired:
// The application may initialise any state necessary to perform work as a leader.
log.Infof("Got event: leader acquired: %v", event.LeaderID())
case LeaderRefreshed:
// Indicates that a new leader ID was generated, as a result of having to remark
// a record (typically as due to an earlier delivery error). This is purely
// informational; there is nothing an application should do about this, other
// than taking note of the new leader ID if it has come to rely on it.
log.Infof("Got event: leader refreshed: %v", event.LeaderID())
case LeaderRevoked:
// The application may block the callback until it wraps up any in-flight
// activity. Only upon returning from the callback, will a new leader be elected.
log.Infof("Got event: leader revoked")
case LeaderFenced:
// The application must immediately terminate any ongoing activity, on the assumption
// that another leader may be imminently elected. Unlike the handling of LeaderRevoked,
// blocking in the callback will not prevent a new leader from being elected.
log.Infof("Got event: leader fenced")
case MeterRead:
// Periodic statistics regarding the harvester's throughput.
log.Infof("Got event: meter read: %v", event.Stats())
}
})
// Start harvesting in the background.
err = harvest.Start()Running goharvest in standalone mode using reaper is the recommended approach for most use cases, as it fully insulates the harvester from the rest of the application. Ideally, you should deploy reaper as a sidecar daemon, to run alongside your application. All the reaper needs is access to the outbox table and the Kafka cluster.
Embedded goharvest is useful if you require additional insights into its operation, which is accomplished by registering an EventHandler callback, as shown in the example above. This callback is invoked whenever the underlying leader status changes, which may be useful if you need to schedule additional workloads that should only be run on one process at any given time.
You can write database records from any app, by simply issuing the following INSERT statement:
INSERT INTO ${outbox_table} (
create_time,
kafka_topic,
kafka_key,
kafka_value,
kafka_header_keys,
kafka_header_values
)
VALUES (NOW(), $1, $2, $3, $4, $5)Replace ${outbox_table} and bind the query variables as appropriate:
kafka_topiccolumn specifies an arbitrary topic name, which may differ among records.kafka_keyis a mandatorystringkey. Each record must be published with a specified key, which will affect its placement among the topic's partitions.kafka_valueis an optionalstringvalue. If unspecified, the record will be published with anilvalue, allowing it to be used as a compaction tombstone.kafka_header_keysandkafka_header_valuesare arrays that specify the keys and values of record headers. When used each element inkafka_header_keyscorresponds to an element inkafka_header_valuesat the same index. If not using headers, set both arrays to empty.
Note: Writing outbox records should be performed in the same transaction as other related database updates. Otherwise, messaging will not be atomic — the updates may be stably persisted while the message might be lost, and vice versa.
The goharvest library comes with a stasher helper package for writing records to an outbox.
When one database update corresponds to one message, the easiest approach is to call Stasher.Stash():
import "github.com/obsidiandynamics/goharvest"db, err := sql.Open("postgres", "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable")
if err != nil {
panic(err)
}
defer db.Close()
st := New("outbox")
// Begin a transaction.
tx, _ := db.Begin()
defer tx.Rollback()
// Update other database entities in transaction scope.
// Stash an outbox record for subsequent harvesting.
err = st.Stash(tx, goharvest.OutboxRecord{
KafkaTopic: "my-app.topic",
KafkaKey: "hello",
KafkaValue: goharvest.String("world"),
KafkaHeaders: goharvest.KafkaHeaders{
{Key: "applicationId", Value: "my-app"},
},
})
if err != nil {
panic(err)
}
// Commit the transaction.
tx.Commit()Sending multiple messages within a single transaction may be done more efficiently using prepared statements:
// Begin a transaction.
tx, _ := db.Begin()
defer tx.Rollback()
// Update other database entities in transaction scope.
// ...
// Formulates a prepared statement that may be reused within the scope of the transaction.
prestash, _ := st.Prepare(tx)
// Publish a bunch of messages using the same prepared statement.
for i := 0; i < 10; i++ {
// Stash an outbox record for subsequent harvesting.
err = prestash.Stash(goharvest.OutboxRecord{
KafkaTopic: "my-app.topic",
KafkaKey: "hello",
KafkaValue: goharvest.String("world"),
KafkaHeaders: goharvest.KafkaHeaders{
{Key: "applicationId", Value: "my-app"},
},
})
if err != nil {
panic(err)
}
}
// Commit the transaction.
tx.Commit()There are handful of parameters that for configuring goharvest, assigned via the Config struct:
| Parameter | Default value | Description |
|---|---|---|
BaseKafkaConfig |
Map containing bootstrap.servers=localhost:9092. |
Configuration shared by the underlying Kafka producer and consumer clients, including those used for leader election. |
ProducerKafkaConfig |
Empty map. | Additional configuration on top of BaseKafkaConfig that is specific to the producer clients created by goharvest for publishing harvested messages. This configuration does not apply to the underlying NELI leader election protocol. |
LeaderGroupID |
Assumes the filename of the application binary. | Used by the underlying leader election protocol as a unique identifier shared by all instances in a group of competing processes. The LeaderGroupID is used as Kafka group.id property under the hood, when subscribing to the leader election topic. |
LeaderTopic |
Assumes the value of LeaderGroupID, suffixed with the string .neli. |
Used by NELI as the name of the Kafka topic for orchestrating leader election. Competing processes subscribe to the same topic under an identical consumer group ID, using Kafka's exclusive partition assignment as a mechanism for arbitrating leader status. |
DataSource |
Local Postgres data source host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable. |
The database driver-specific data source string. |
OutboxTable |
outbox |
The name of the outbox table, optionally including the schema name. |
Scribe |
Scribe configured with bindings for log.Printf(); effectively the result of running scribe.New(scribe.StandardBinding()). |
The logging façade used by the library, preconfigured with your logger of choice. See Scribe GoDocs. |
Name |
A string in the form {hostname}_{pid}_{time}, where {hostname} is the result of invoking os.Hostname(), {pid} is the process ID, and {time} is the UNIX epoch time, in seconds. |
The symbolic name of this instance. This field is informational only, accompanying all log messages. |
Limits.MinPollInterval |
100 ms | The lower bound on the poll interval, preventing the over-polling of Kafka on successive Pulse() invocations. Assuming Pulse() is called repeatedly by the application, NELI may poll Kafka at a longer interval than MinPollInterval. (Regular polling is necessary to prove client's liveness and maintain internal partition assignment, but polling excessively is counterproductive.) |
Limits.HeartbeatTimeout |
5 s | The period that a leader will maintain its status, not having received a heartbeat message on the leader topic. After the timeout elapses, the leader will assume a network partition and will voluntarily yield its status, signalling a LeaderFenced event to the application. |
Limits.QueueTimeout |
30 s | The maximum period of time a record may be queued after having been marked, before timing out and triggering a remark. |
Limits.MarkBackoff |
10 ms | The backoff delay introduced by the mark thread when a query returns no results, indicating the absence of backlogged records. A mark backoff prevents aggressive querying of the database in the absence of a steady flow of outbox records. |
Limits.IOErrorBackoff |
500 ms | The backoff delay introduced when any of the mark, purge or reset queries encounter a database error. |
Limits.MaxInFlightRecords |
1000 | An upper bound on the number of marked records that may be in flight at any given time. I.e. the number of records that have been enqueued with a producer client, for which acknowledgements have yet to be received. |
Limits.SendConcurrency |
8 | The number of concurrent shards used for queuing causally unrelated records. Each shard is equipped with a dedicated producer client, allowing for its records to be sent independently of other shards. |
Limits.SendBuffer |
10 | The maximum number of marked records that may be buffered for subsequent sending, for any given shard. When the buffer is full, the marker will halt — waiting for records to be sent and for their acknowledgements to flow through. |
Limits.MarkQueryRecords |
100 | An upper bound on the number of records that may be marked in any given query. Limiting this number avoids long-running database queries. |
Limits.MinMetricsInterval |
5 s | The minimum interval at which throughput metrics are emitted. Metrics are emitted conservatively and may be observed less frequently; in fact, throughput metrics are only emitted upon a successful message acknowledgement, which will not occur during periods of inactivity. |
Comparison of messaging patterns